
Is your ML project worth trying?

Any data science project starts with an idea. Ideas often come from various business stakeholders (for example, the marketing department, finance department, inventory management, etc). Some are great, and we bet data scientists can’t wait to get busy and try out all kinds of fancy algorithms.
However, even the experimentation phase can get expensive, and we believe that all projects should start with the business case. In this article, we will talk about the impact, risk, and feasibility assessment of data science projects — something most data scientists do not want to think about.

Impact assessment
Under impact, we understand the business value behind an idea. At this stage, it is also important to understand how we can prove the value of an idea, in other words, what kind of KPIs we have. It is good practice to do an estimation of expected development and production costs for the project since it has a direct impact on the business value.
For example, there is a version of a recommender developed by a third party implemented on the website at a checkout page. Business stakeholders (the online department) are not incredibly happy about the model quality and want to develop an in-house solution. They believe that an in-house solution can lead to a 10% increase in revenue coming from the recommender. If the current recommender is responsible for €1 million in revenue per year, we expect the impact of the in-house solutions to be €1,1 million per year. Revenue from products added to the basket after the recommender suggestion is the KPI for this use case.
Risk assessment
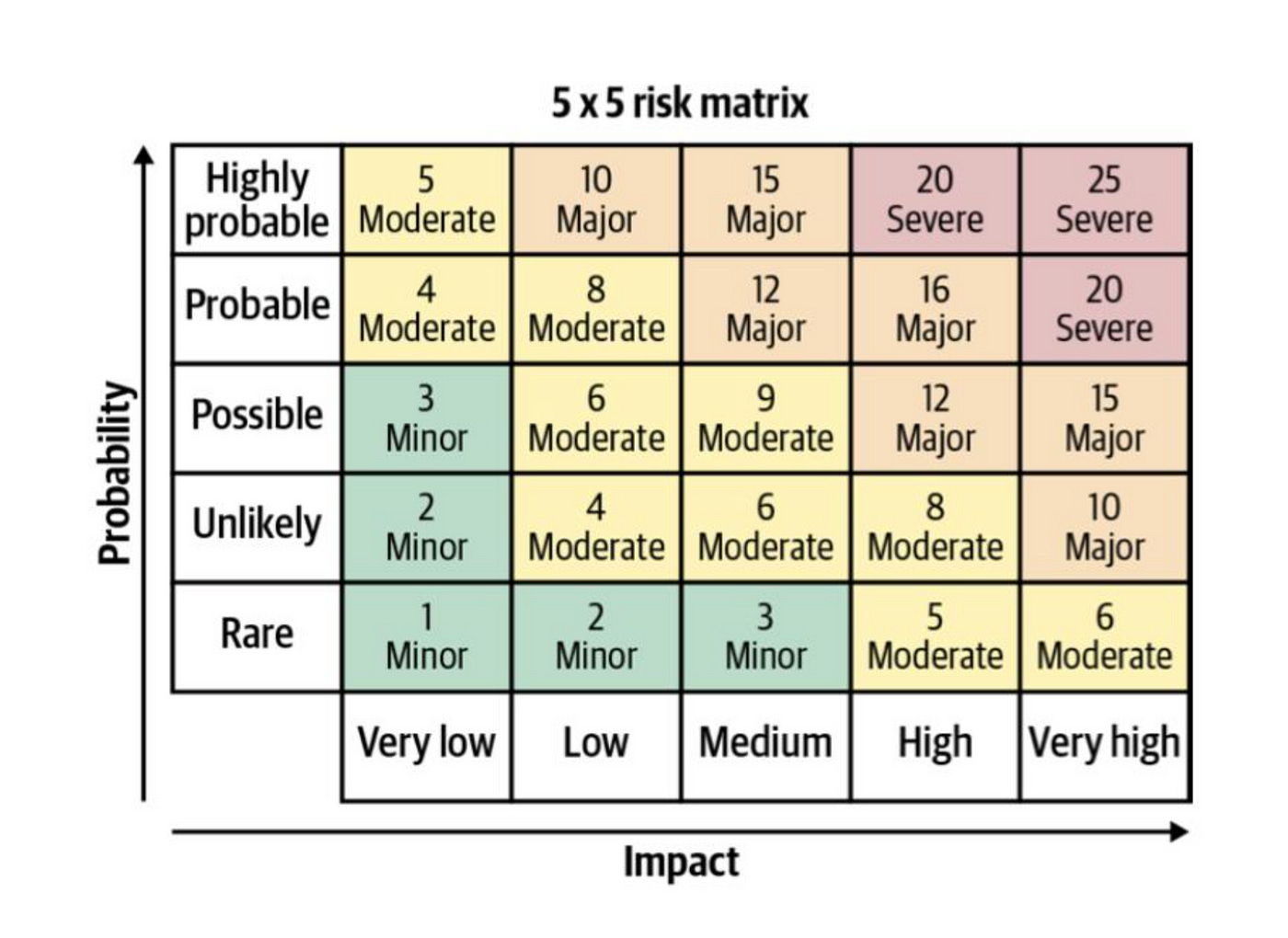
Machine learning risk assessment can be done using a 5x5 risk matrix with impact on one side and the likelihood of risk event on the other. There are two types of risk events: the model is unavailable, or the model is returning bad predictions.
The model can be unavailable for a certain period due to the following reasons:
The infrastructure needed for model training/serving is not available
The model was promoted to the production environment, but infrastructure in different environments was not aligned
Data schema has changed, and the model cannot be retrained/ cannot return predictions
Updates in runtime/ software version that caused incompatibility
Some of the problems mentioned above occurred, and the skills necessary to fix these problems are lost
The model can be returning bad predictions due to the following reason:
Model accuracy has decreased over time
Given sample is an outlier that the model has not seen before
The model was not trained keeping fairness in mind (for example, the model is biased towards gender/ nationality because gender- or nationality-related features are indirectly used for model training)
Some of the problems mentioned above occurred, and the skills necessary to fix these problems are lost
The likelihood of these risk events is heavily dependent on the level of MLOps maturity within the organization. Impact in the risk matrix is not just business value behind the machine learning use case, it is about how critical it is if a risk event happens. For example, if a search algorithm is implemented on the website of an online shop, and the search API is not responding, then customers cannot find products on the website and cannot add it to the cart, the impact can be in thousands of euros per hour. Even if a fallback mechanism is implemented and working properly, it can still lead to significant revenue loss.
Idea feasibility
When talking about idea feasibility, we need to think about whether we have everything needed to start an experiment. The following aspects are crucial for a data science experiment:
Legal & Ethics
Data availability
Infrastructure availability
Right skillset
GDPR has significant implications for machine learning projects. For example, if customer data is intended to be used for specific marketing activities, it might be obligatory to get customer consent first, which makes some ideas less feasible, especially if customer consent is not easy to obtain. It is important to check for ethical aspects of the projects and to make sure that the data available for machine learning projects is not biased in a certain way.
Since many data science projects use infrastructure as a service proposition (Microsoft Azure, GCP, or AWS), under infrastructure availability we mean that all cloud components needed for an experiment are available and have appropriate security setup. Under data availability, we mean that data scientists have access to production data to experiment.